Mathematically proven zero defect software
We empower developers to deliver mathematically proven zero-defect software
Unbreakable software safety, security, and reliability

Build Embedded Software You Can Trust

Safety You Can Rely On
Mathematically eliminate risks like buffer overflows and undefined behaviors.

Robust Security
Deliver software free of memory leaks and runtime errors.

Proven Reliability
Guaranteed confidence that your software performs flawlessly across all execution paths every time.
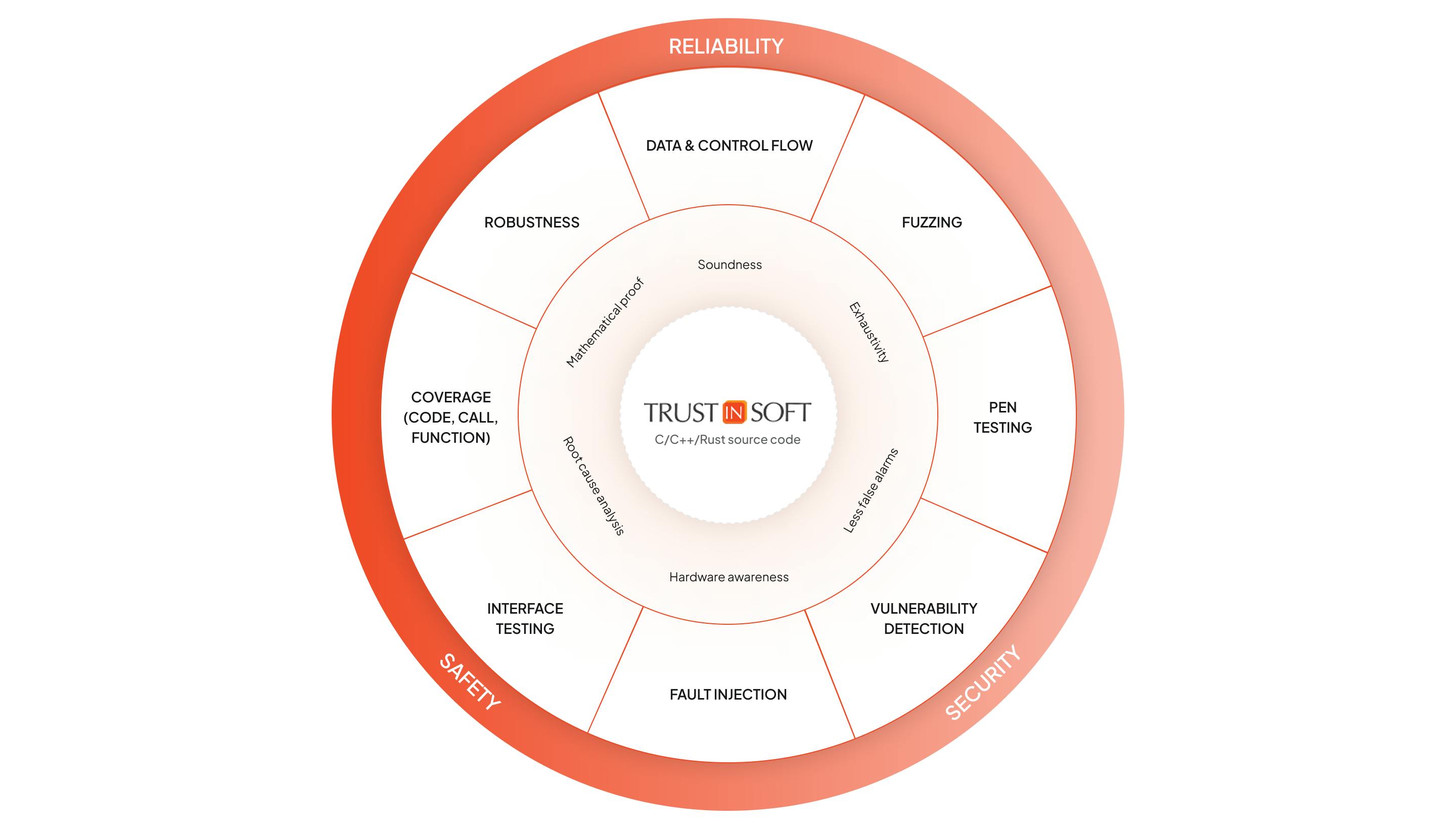
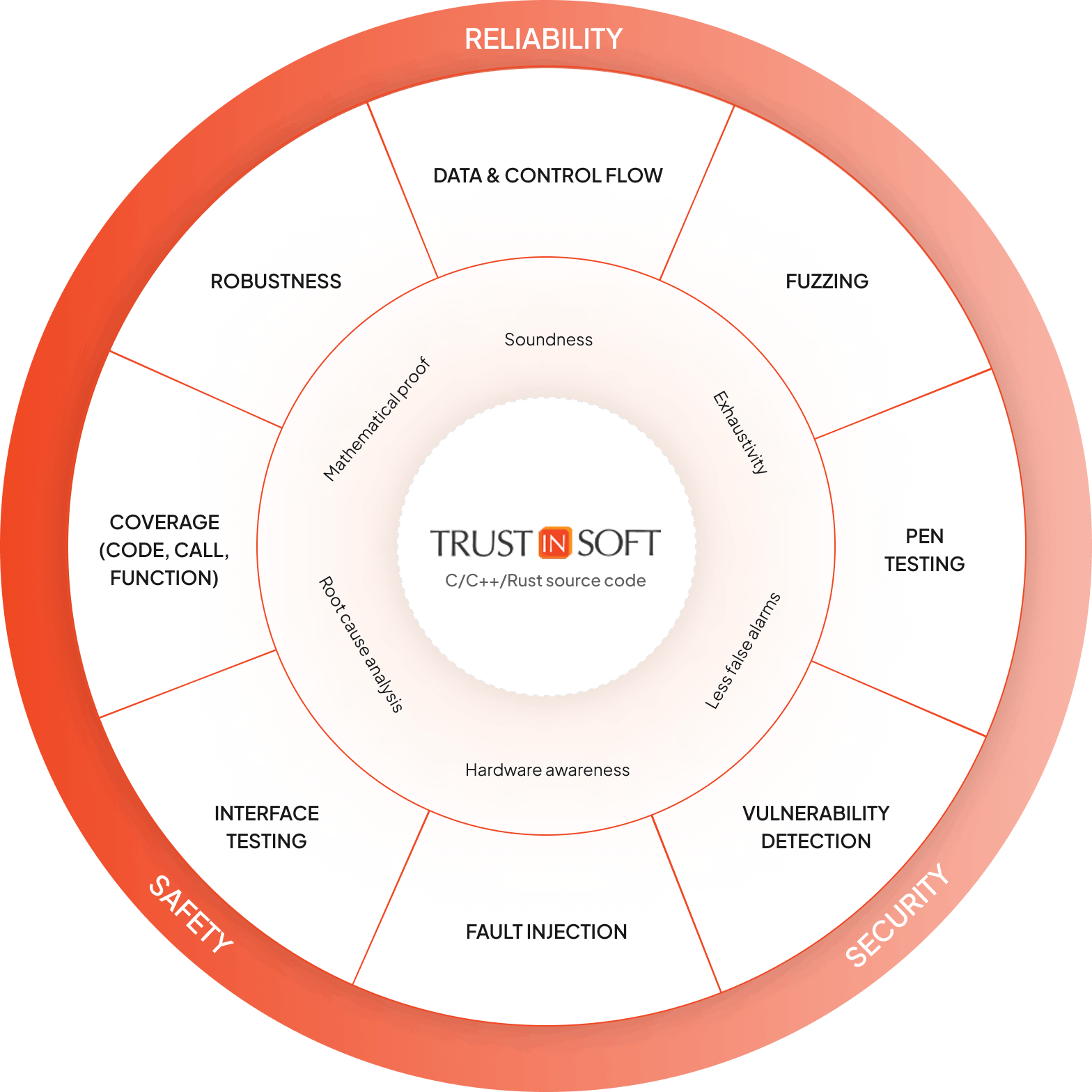
The TrustInSoft Difference
Harness the power of abstract interpretation with an all-in-one hybrid analysis for unrivaled accuracy with formal verification.

Detect and eliminate runtime errors with up to 100% code coverage.
Protect against memory-related vulnerabilities such as leaks and use-after-free errors.

Achieve safety certifications faster with proven methods.
Powered by Mathematics, Trusted by Experts


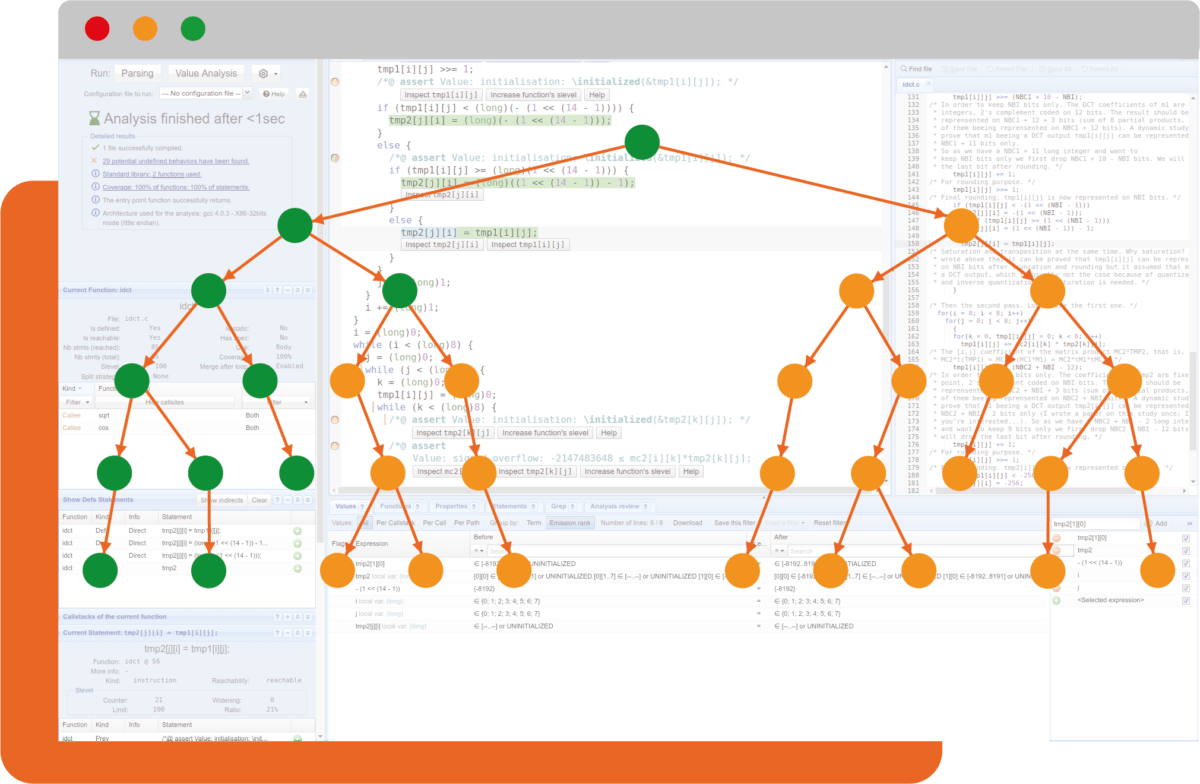
Success stories
TrustInSoft is recognized by the National Institute of Standards and Technology (NIST) for its ability to prove the absence of entire families of bugs. TrustInSoft’s clients use TrustInSoft Analyzer to develop safer and more secure products. Read about their experiences using TrustInSoft Analyzer here!
Read our use cases






“TrustInSoft Analyzer does improve the quality of our products. They have spotted multiple bugs and flaws in our source code, and reduced the time spent in software testing.”
-Gartner Peer Insights feedback
Read Reviews






About TrustInSoft
Recognized by the NIST, TrustInSoft was founded in 2013 by three former researchers of The French Alternative Energies and Atomic Energy Commission. Today, TrustInSoft supports international customers in a variety of industries, including aeronautics, telecommunications, industrial IoT and automotive.
Discover the company

